Frame-of-Fancy
Artificial Intelligence is an increasingly relevant topic and though we tend to focus on the technical advantages of it, I am incredibly interested in the artistic application of machine learning techniques. As such, I have set out to combine Artificial Intelligence and photography as art, and have created a machine learning technique to achieve this.
The artistic approach I took involved the inclusion of a photo frame as a prop. The final pipeline would be as follows: to take photos including the photo frame, have an AI model recognize the photo frame and, given a “style” image, transform the inside of the photo frame and its contents via style transfer into the given style. This requires two AI models - one to find the frame, and one to transfer the style image onto the input image.
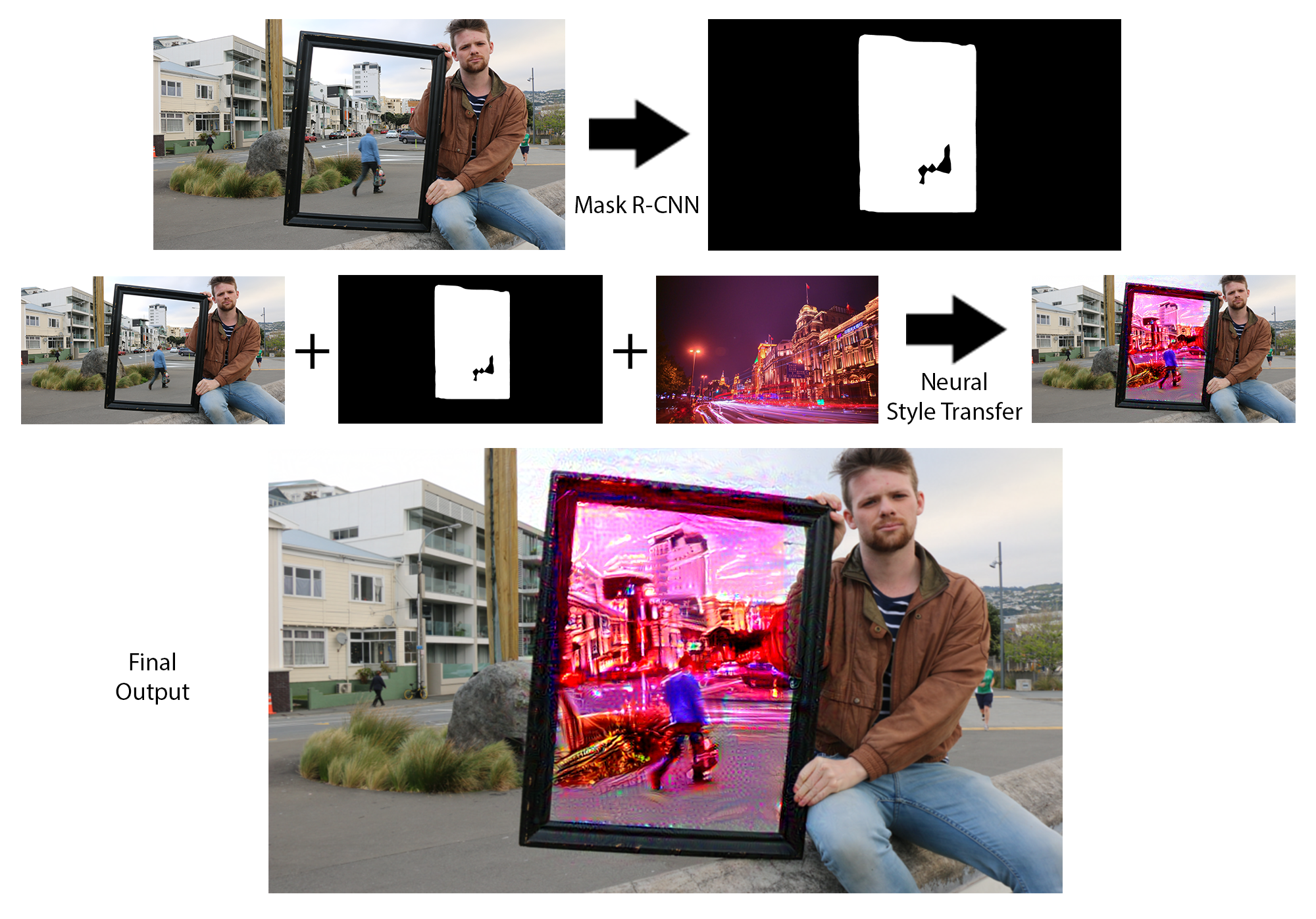
Image Segmentation
To train a model to recognize the photo frame, I first had to take around 150 photos including the frame. To stay consistent I kept it one exact photo frame, at roughly the same distance from the camera in each photo, around the same time of day as to keep the lighting and contrast consistent also. To avoid too much consistency however, I made sure to keep the contents of the frame vary in significant ways, as well as whether or not people were in the photo, holding the frame, or wearing the same clothing. Both consistency and variability play an important role in keeping the training both accurate and reliable.
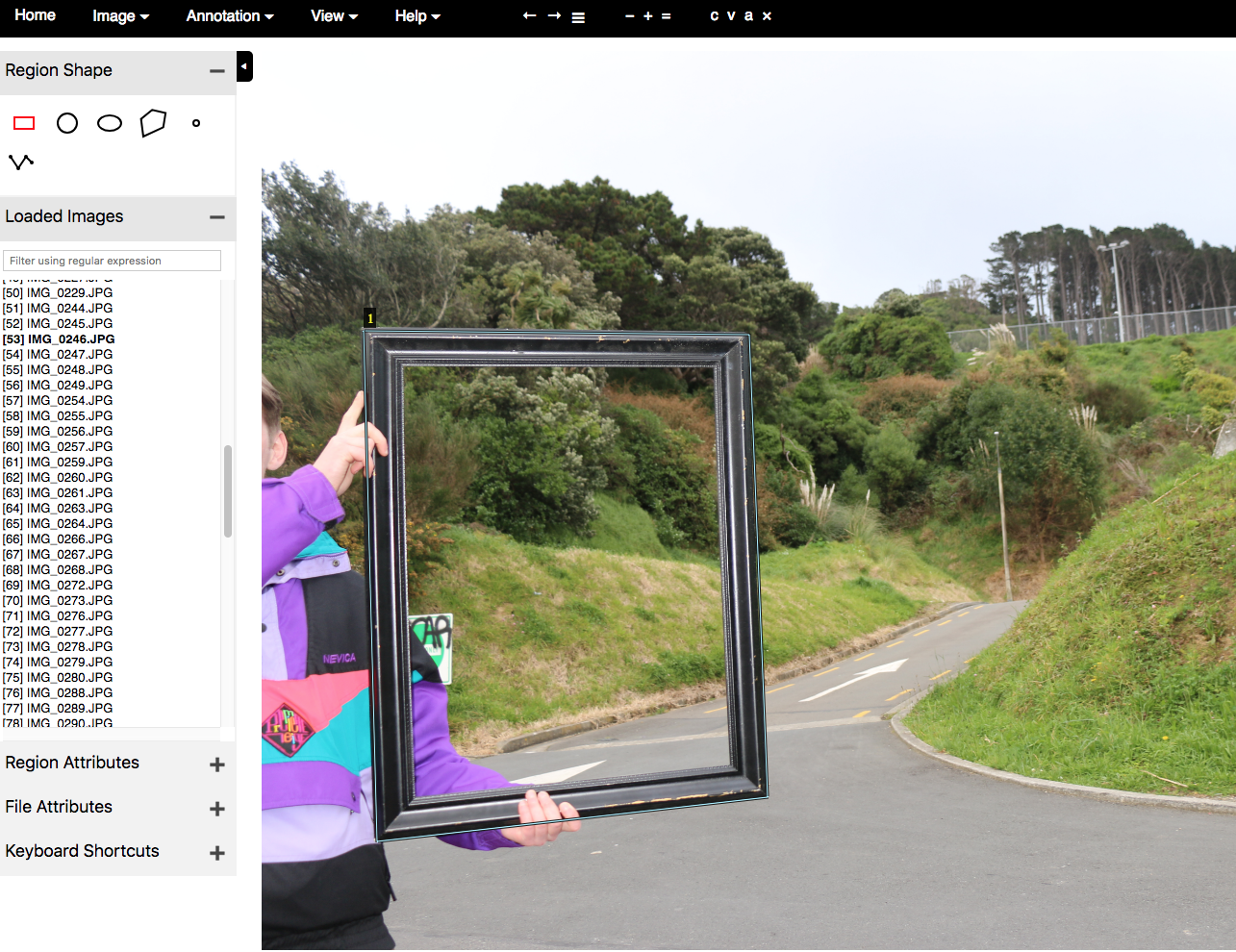
Having taken these photos I used VGG Image Annotator to label the frame and its contents in each image as shown in fig.1. I labelled the outside of the frame as oppose to the inside, also including any fingers or objects obscuring a part thereof, such as to keep each label to 4 points, and potentially provide some artistic inaccuracies. I fed all of these annotated images into Mask R-CNN to train my final model.
Style Transfer
I used a pre-trained form of Neural Style Transfer to transform the inside of the frame. I found a model that takes in a mask as well as input and style image, to only stylize the white portion of the mask and leave the rest as the original input. With the models in a working pipeline all that is left is to find suitable input and style images.
Initially I had some trouble with messy outputs which I thought was the fault of the style transfer model, but it was in fact the input images. This particular style transfer model works best on highly detailed, large area spaces, where I was using smaller plain images. In my final outputs I had taken photos of the frame with much more busy interiors, detailed backgrounds and far in the distance with the frame itself close to the camera.

Conclusion
Machine learning is a powerful tool in almost any context, and it aids art and design just as much. Bringing it into the tangible realm proved an interesting technique that I hope to see others use in the future. Specificity is important in training an image segmentation model as well as staying consistent in your dataset. Understanding the AI models you are working with will also aid in creating art using machine learning, and working with the strengths of your models will create better results.
This technique is an interesting entrance into affecting the AI output with a physical object. It fits well with photography and I hope to continue in future work to try and create a similar tool for video creation.
References
1 “VGG Image Annotator (VIA) - University of Oxford.” http://www.robots.ox.ac.uk/~vgg/software/via/. Accessed 24 Oct. 2018.
2 “GitHub - matterport/Mask_RCNN: Mask R-CNN for object detection ….” https://github.com/matterport/Mask_RCNN. Accessed 24 Oct. 2018.
3 “GitHub - titu1994/Neural-Style-Transfer: Keras Implementation of ….” https://github.com/titu1994/Neural-Style-Transfer. Accessed 24 Oct. 2018.